Person Interaction Detection
To detect text segments that may convey person interaction.

To detect text segments that may convey person interaction.
To extract keyword for expressing interaction between persons.

To recognize sentiment behind person interactions.
To construct a network for visualizing social interactions.
The web has become a powerful medium for disseminating information about diverse topics, such as political issues and sports tournaments. While people can easily find documents that cover various perspectives of a topic, they often have difficulty assimilating the knowledge contained within large documents. This problem has motivated the development of several topic mining methods to help readers digest enormous amounts of topic information. The extracted themes and summaries distill the topic contents clearly; however, readers still need to expend a great deal of time to comprehend the extracted information about unfamiliar topics.
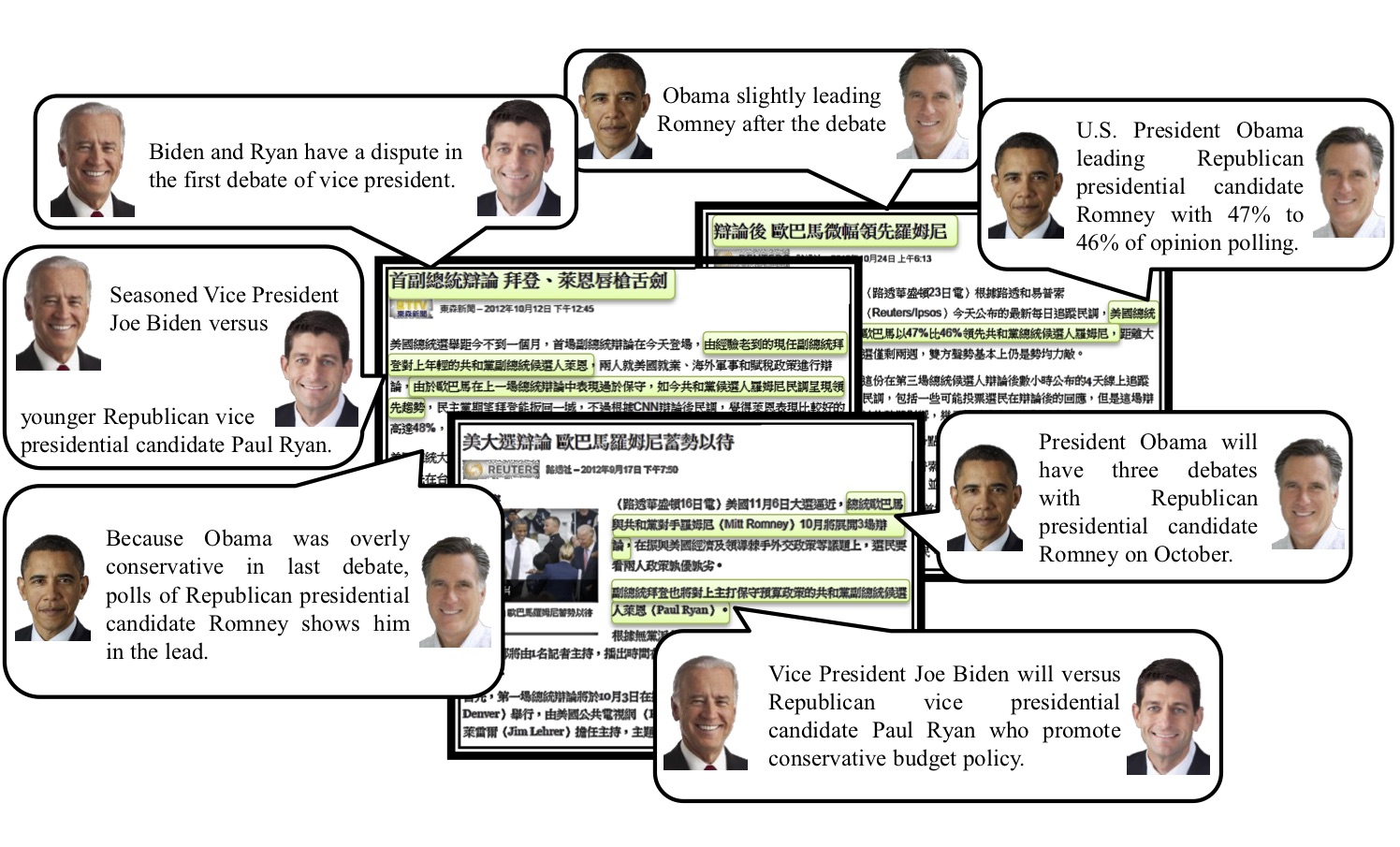
Basically, a topic is associated with specific times, places, and persons. The interactions between the persons (called topic persons hereafter) constitute the storyline of the topic, and thereby knowing topic person interactions is critical to readers to comprehend numerous topic documents. In this paper, we investigate the topic person interaction detection which involves identifying text segments in topic documents that convey interactions between topic persons. For instance, given the documents about the 2012 U.S. presidential election, topic person interaction detection designates the text segments that mention the interaction of the key persons of different camps, as shown in Figure 1. In addition to facilitating topic comprehension, topic person interaction detection could also benefit many information retrieval and natural language processing tasks. For instance, topic mining methods could incorporate the segments of person interactions into the generated topic summaries to present the development of topics. Moreover, as the expressions of person interactions are usually with sentiments, sentiment analysis methods which detect textual units with positive or negative orientations could focus on the segments of person interactions to distill their results. On the other hand, question answering systems would provide correct answers of who-type questions regarding person interactions. Hence, detecting the interaction of topic persons is worth investigating.
The evaluation metrics are the precision, recall, and F1-score. The F1 value is used to determine relative effectiveness of the compared methods. Following are the performance evaluation criteria for the two proposed tasks:
Person interaction detection (PID): This task is a binary classification problem. Systems constructed by the participants are asked to answer “Y” or “N” for a given text segment. If a human infers that the text segment conveys interaction between given person mentions, then the answer is “Y”. Otherwise, the answer is “N”.
Person interaction extraction (PIE): When text segments convey person interactions, participants’ systems are asked to extract the keywords that can be used to express the interaction. The extracted keywords are regarded as correct if it is exactly identical to the gold standard, or if it partially matches the gold standard with three dissimilar words allowed.
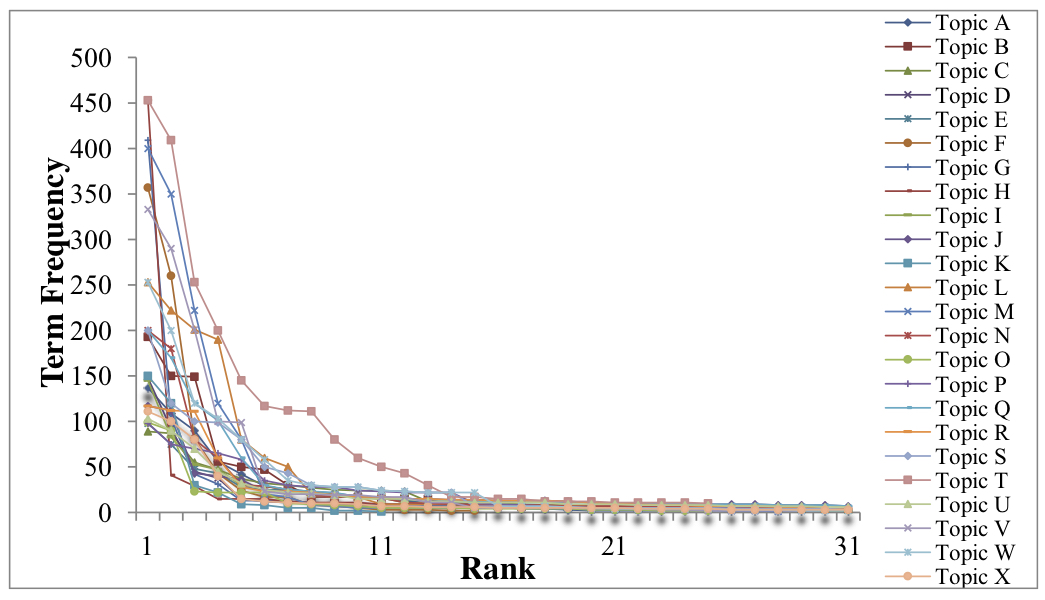
To the best of our knowledge, there is no official corpus for person interaction detection. The entity relations defined in the Automatic Content Extraction (ACE) datasets, such as capital of, are static and irrelevant to person interactions. Therefore, we compiled a data corpus for the performance evaluations. The data corpus comprises 24 important topics from 2004 to 2014. Each topic consists of 100 Chinese news documents collected from Yahoo News. We employed Stanford NER (https://nlp.stanford.edu/software/CRF-NER.html) to tag person names mentioned in the topic documents. The tagging produced 15,370 person names that represent 665 unique persons. We noticed that many of the person names rarely occurred in the topic documents and the rank-frequency distribution of the person names followed Zipf’s law as shown in Figure 2. The low frequency names usually refer to persons irrelevant to the topic (e.g., journalists). To reduce their influence on system performance, for each topic, we evaluated the first frequent person names whose frequency reached 70% of the total person name frequency in the topic documents.
All the evaluated person names represent important topic persons. The candidate segment generation algorithm extracts 9,632 candidate segments from the topic documents. Among them, 4,019 segments were labeled as interactive by two linguistic experts. The Kappa statistic of the labeling process is 0.845, which means that our data corpus is reliable. As shown in Table 1, a great portion (i.e., 56.4%) of interactive segments are inter-clausal. Besides, around half (49.8%) of intra-clausal segments are non-interactive. In other words, persons occur in the same clauses generally have no interaction and the interaction of persons is usually narrated by a sequence of clauses. The distributions reveal that mining person interactions is not trivial.

1. Yung-Chun Chang, Chien Chin Chen, and Wen-Lian Hsu, "SPIRIT: A Tree Kernel-based Method for Topic Person Interaction Detection (Extended abstract)," 2017 IEEE International Conference on Data Engineering, pages 13-14, April 2017.
2. Yung-Chun Chang, Pi-Hua Chuang, Chien Chin Chen and Wen-Lian Hsu, "FISER: A Feature-based Detection System for Topic Person Interactions," Computational Intelligence, volume 2017, pages 5, May 2017.
3. Yung-Chun Chang, Chien Chin Chen, and Wen-Lian Hsu, "SPIRIT: A Tree Kernel-based Method for Topic Person Interaction Detection," IEEE Transactions on Knowledge and Data Engineering (TKDE), volume 28, number 9, pages 2494-2507, August 2016.
4. Yung-Chun Chang, Chien Chin Chen, and Wen-Lian Hsu, "A Composite Kernel Approach for Detecting Interactive Segments in Chinese Topic Documents," the 9th Asia Information Retrieval Societies Conference (AIRS 2013), Lecture Notes in Computer Science, pages 215-226, December 2013.
5. Yung-Chun Chang, Pi-Hua Chuang, Chien Chin Chen, and Wen-Lian Hsu, "FISER: An Effective Method for Detecting Interactions between Topic Persons," the 8th Asia Information Retrieval Societies Conference (AIRS 2012), Lecture Notes in Computer Science, pages 275-285, December 2012.