Taiwam e-Clinic Dataset
Motivation
As healthcare specialization advances, patients increasingly struggle to select the appropriate medical departments due to the intersectionality of their symptoms, which complicates the diagnosis and treatment process. To address this issue, the development of artificial intelligence has propelled digital triage systems to the forefront, becoming crucial tools in guiding patients effectively through this complex landscape. This study conducts a comprehensive comparative analysis of pre-trained language models (PLMs), including Bidirectional Encoder Representations from Transformers (BERT), RoBERTa, BlueBERT, Llama, and the Taide series tailored for Mandarin Chinese, on patient data from Taiwan's online medical consultation platform, Taiwan e-Clinic. The focus is on evaluating the efficacy of these models in recommending patient visits, specifically for Mandarin Chinese-speaking patients, to identify the most effective framework for clinical application. Our findings indicate significant differences in the models' abilities to recommend appropriate departments, which has important implications for enhancing digital healthcare services, especially in post-pandemic scenarios. The results demonstrate that PLMs have the potential to understand patient complaints and improve healthcare accessibility, enabling quicker medical recommendations.
Methodology
In our experiments, the performance evaluation metrics included precision, recall, and F1-score. And we used macro-average to compute the average performance.
Our study has demonstrated that RoBERTa outperforms other language models in classifying medical departments from patient complaints. This superiority is attributed primarily to its extensive pre-training and dynamic masking, which collectively enhance its semantic understanding and generalization capabilities. Despite BlueBERT's specialization in medical terminology, its performance is compromised in the context of the more colloquial language prevalent in online consultations, rendering RoBERTa more effective. Furthermore, models like RoBERTa significantly surpass LLMs in classification tasks. LLMs, while adept at generating coherent text, tend to falter in precision-based classification, with hallucination issues further undermining their performance. Addressing these hallucination problems and enhancing the training of models specifically for Mandarin Chinese will be pivotal in our future research.
Additionally, our keyword trend analysis revealed that online medical consultations peaked during the mid to late stages of the pandemic (2021-2022), driven by isolation measures and the promotion of telemedicine. However, the number of consultations witnessed a decline post-pandemic (2023), falling below pre-pandemic levels, likely due to patient skepticism and discomfort with virtual interactions. This trend underscores a significant research opportunity to further enhance and optimize online consultation platforms, aiming to restore patient confidence and improve the overall efficacy of digital healthcare services.
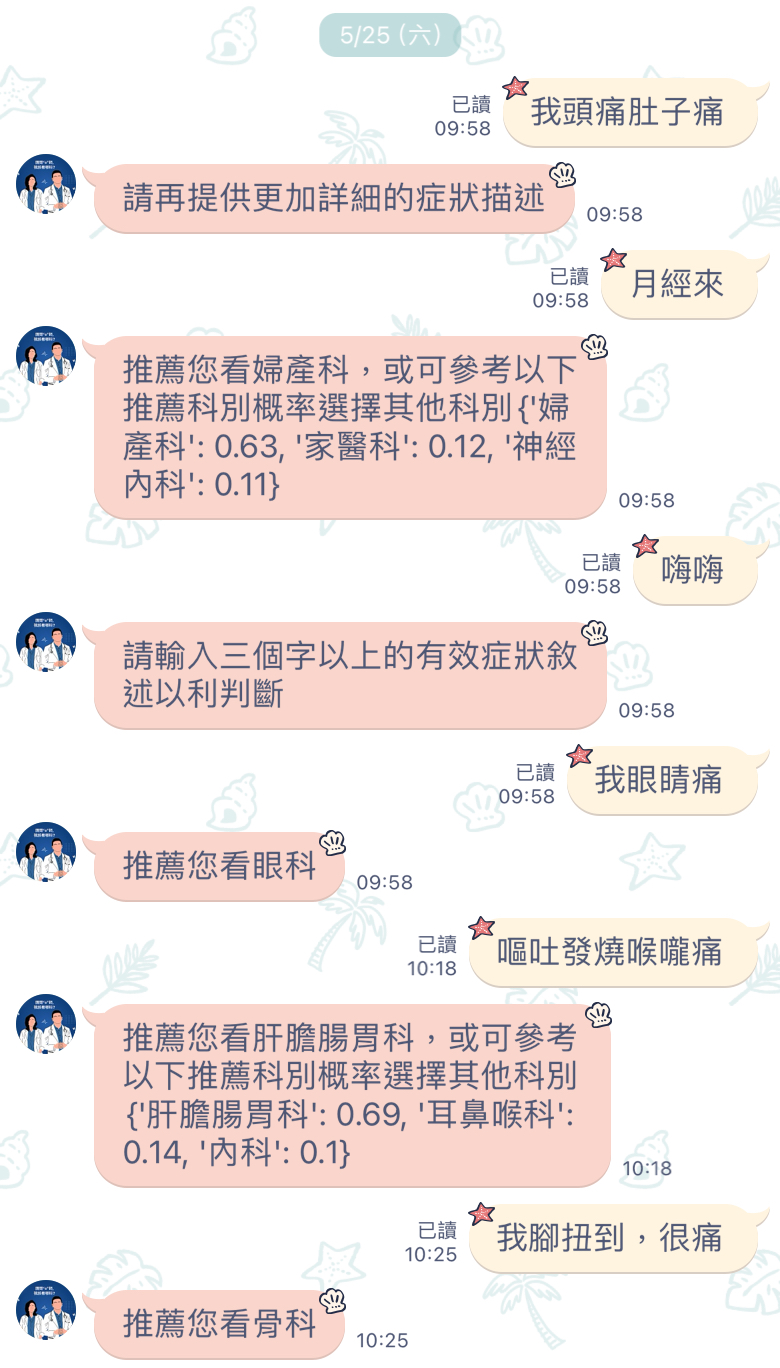
Online consultation LineBot
Considering that most people in Taiwan prefer using LINE as their social platform, we chose to integrate the model with a LineBot to reach a wider audience, developing it into a one-on-one online consultation virtual doctor.
After the user inputs symptom keywords:
1. If the input is fewer than 3 characters, it is deemed invalid, and the user will be prompted to input symptom keywords with at least 3 characters.
2. If the probability of the first recommended department is greater than 0.5 and no other department has a probability greater than 0.1, only the first department will be recommended.
3. If the probability of the first recommended department is greater than 0.5 and there are other departments with probabilities greater than 0.1, both the first department and departments with probabilities over 0.1 will be displayed.
4. If the probability of the first department is less than 0.5, the user will be prompted to enter more detailed symptom keywords (this input will be saved for the next analysis).
5. If three attempts with valid symptom keywords still result in no department having a probability over 0.5, the system will indicate “unable to diagnose.” The user will be advised to consult a healthcare provider or enter more specific symptom details.